A query is SARGable (Search ARGument able) if a database engine can take advantage of index.
What makes a query non SARGable?
These are the few factors that makes a query non sargable.
1. Put a column inside a function in the where clause.
select
s.SalesOrderID,
s.SalesPersonID,
s.OrderDate,
s.SalesOrderNumber
from Sales.SalesOrderHeader s
where YEAR(s.OrderDate) = 2011; -- Row Retrieved: 1607 and Row read : 31465
Note: I have created covering index on the OrderDate:
create nonclustered index IX_Sale_OrderDate on Sales.SalesOrderHeader(OrderDate)
include
(
SalesOrderID,
SalesPersonID,
SalesOrderNumber
);
Let’s look at the execution plan:
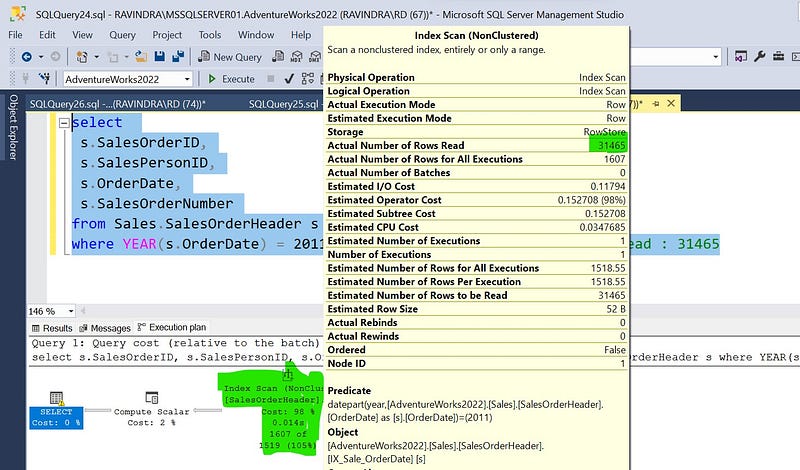
There are total of 1607 rows for year 2011, but total number of row reads are 31465. Let me explain what happened here. The OrderDate has a non-clustered index but database engine won’t optimize it and this query is going to read all the rows from the table. Because, YEAR function will evaluate against each row that causes the non clustered index scan (scan a whole index which have all the needed columns because of covering index). If you don’t understand scans and seeks, I would refer you to check this article.
We can re-write the query to optimize the index on OrderDate.
select
s.SalesOrderID,
s.SalesPersonID,
s.OrderDate,
s.SalesOrderNumber
from Sales.SalesOrderHeader s
where s.OrderDate>= '2011-01-01' and s.OrderDate<='2011-12-31'; -- rows retrieved 1607 and row read: 1607
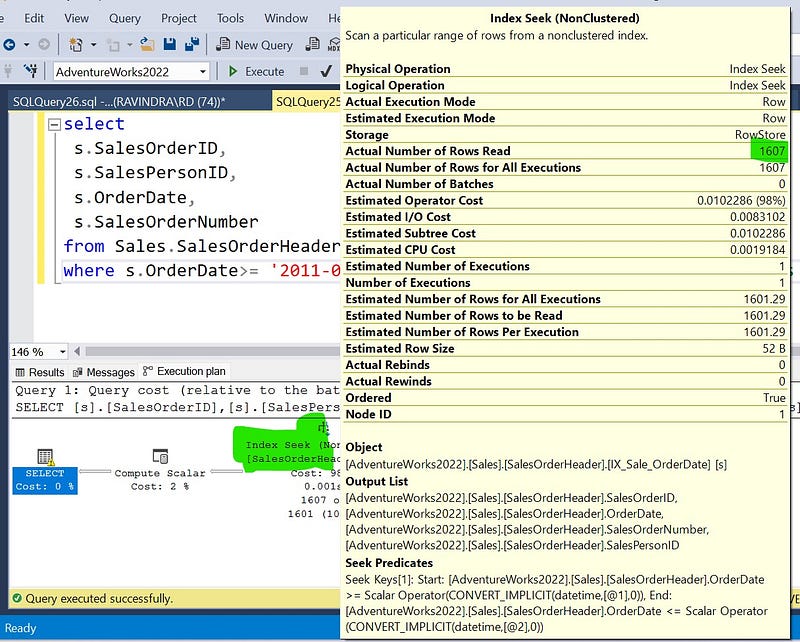
Now this query is optimizing the index.
2. Using the leading wildcards in the LIKE keyword
SELECT
b.*
FROM Book b
WHERE b.Title Like '%fairy%';
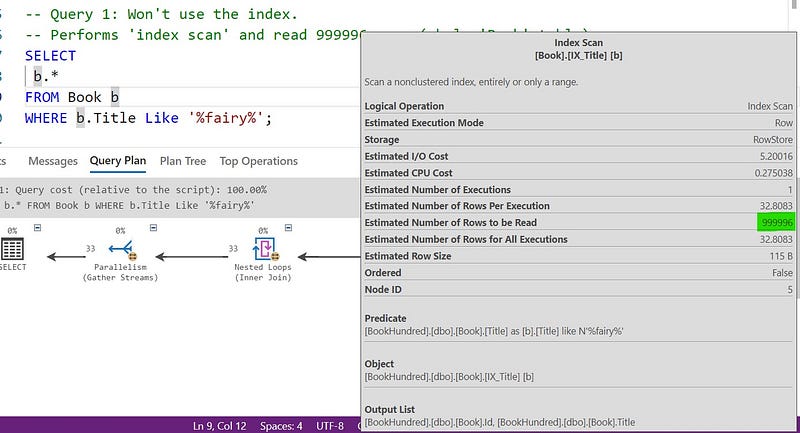
The query defined above won’t use the index which is defined on the column ‘Title’. It performs an ‘index scan’ and read all the rows. Because, we need to scan all the rows where a title contains a string ‘fairy’.
Let’s re-write the query:
SELECT
b.*
FROM Book b
WHERE b.Title Like 'fairy%';
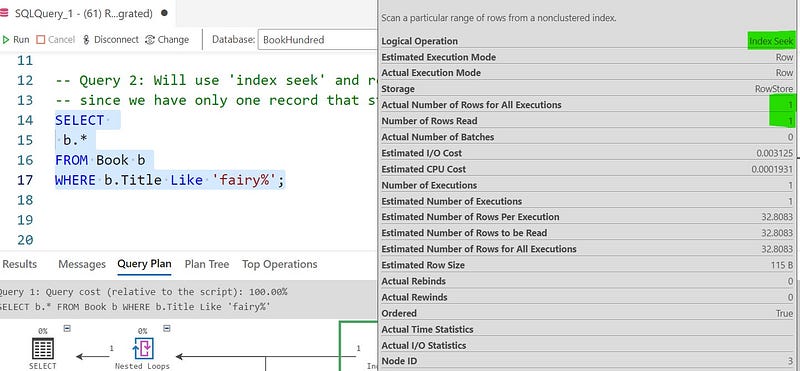
This query uses the index and read only appropriate rows. Since the ‘Book’ table have only 1 record which starts with title ‘fairy’, so it will read only 1 row.
3. Implicit conversions (in the table side)
When we compare two values with different data types, the sql server converts the lower-precedence data type to higher-precedence data type. Let’s look at the example below (which I have taken from the article mssqltips and I am using AdventureWorks2022 database).
-- Note: `CardNumber` is `nvarchar`, there is an index on the `CardNumber`
-- and we are comparing it with an integer 11119775847802
SELECT
CreditCardID,
CardNumber
FROM Sales.CreditCard
WHERE CardNumber = 11119775847802;
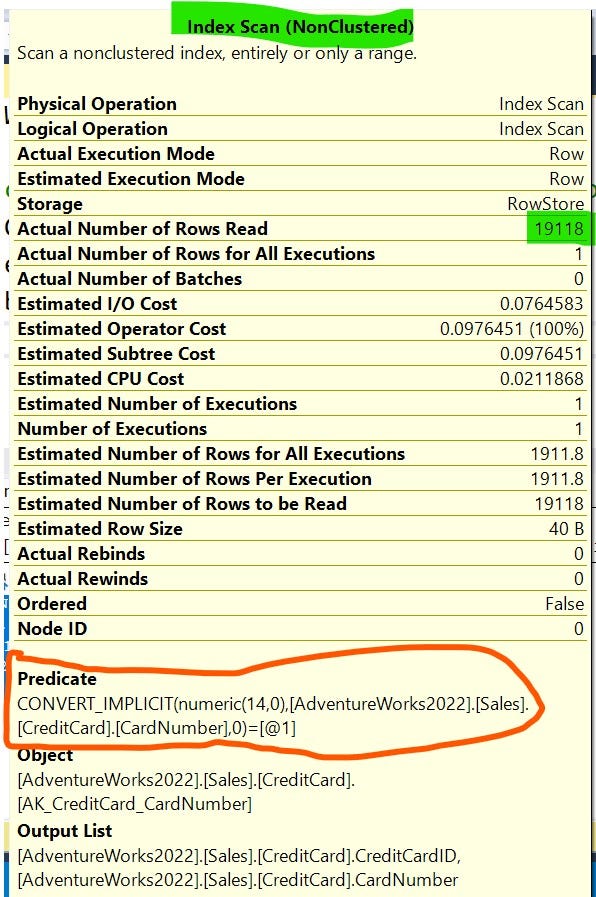
Here CardNumber is a type of nvarchar and we are comparing it with an integer. CardNumber has an index. There is only one record with CardNumber=11119775847802, so it should read only 1 row to fetch the record. But that won’t happen. Sql server database engine reads all the rows to find this record. You wonder why? Ok let me explain.
CardNumber is a nvarchar type, we are searching for record with CardNumber = 11119775847802 which is an integer type. Instead of converting 11119775847802 to the nvarchar, the SQL Server converts all CardNumber rows to an integer, leading to index scan. Are you getting the problem here. We just need a single record, whose CardNumber is **11119775847802**, for that the whole table is being scanned.
So, use ‘11119775847802’instead of 11119775847802 , which avoids implicit conversion in a table side, as shown below:
SELECT
CreditCardID,
CardNumber
FROM Sales.CreditCard
WHERE CardNumber = '11119775847802';
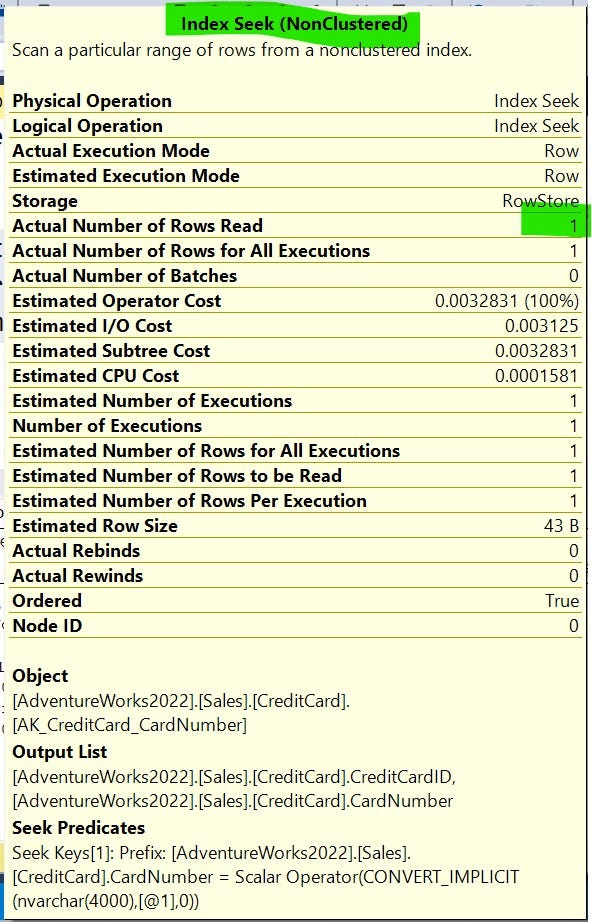
This query will read 1 row only and use the index effectively.
Note: Sometimes sql server smartly handles the implicit conversion and avoid conversion in the table side, like in this example:
SELECT
soh.SalesOrderID,
soh.SalesOrderNumber,
soh.ModifiedDate
FROM Sales.SalesOrderHeader soh
WHERE soh.SalesOrderID= '43668';
The query above won’t perform an implicit conversion on the table side. Rather than converting all SalesOrderId to nvarchar, it just have converted ‘43668’ to integer.
I have tested various queries, where I am comparing the string values (eg. ‘43668’) to an integer type columns (eg. SalesOrderID). What I found is, sql server handles it very well and converts the comparing value not all the rows. That causes the index seek.
So, sometimes sql optimizer also optimize things.
4. Using optional parameter (where column_name=@some_parameter or @some_parameter is NULL)
I am the victim of this one. I have been doing this for my entire life whenever I was writing raw sql queries (however I have used EF most of the time). And I was not even aware that it is not a good query.
Let’s look at the example :
create or alter procedure GetBooks
@SearchTerm nvarchar(40)=null
as
begin
set nocount on;
select * from Book
where @SearchTerm is null or Title like @SearchTerm+'%';
end
go
-- execute the procedure
exec GetBooks @SearchTerm='The Epic Of Gilgamesh'; -- returns 1 row
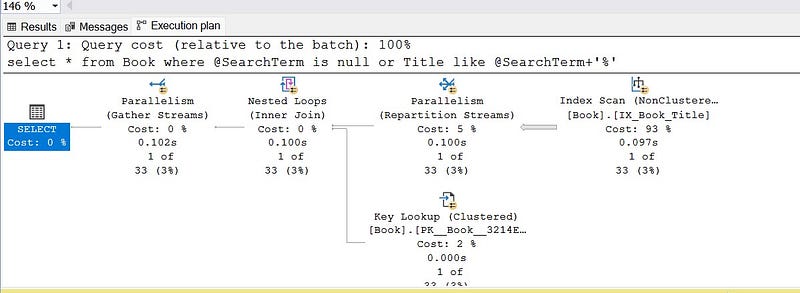
The above query wont use the index on Title and end up in index scan (scanning all the rows).
We can solve it in two ways:
(i). Using dynamic sql
create or alter procedure GetBooks
@SearchTerm nvarchar(40)=null
as
begin
set nocount on;
declare @SQL nvarchar(max);
set @SQL = N'SELECT * FROM Book WHERE 1 = 1';
if @SearchTerm is not null
begin
set @SearchTerm = @SearchTerm+'%';
set @SQL += N' AND Title LIKE @SearchTerm';
end
exec sp_executesql @SQL, N'@SearchTerm nvarchar(40)', @SearchTerm;
end
go
-- Executing the procedure
exec GetBooks @SearchTerm='The Epic Of Gilgamesh'; -- return 1 row
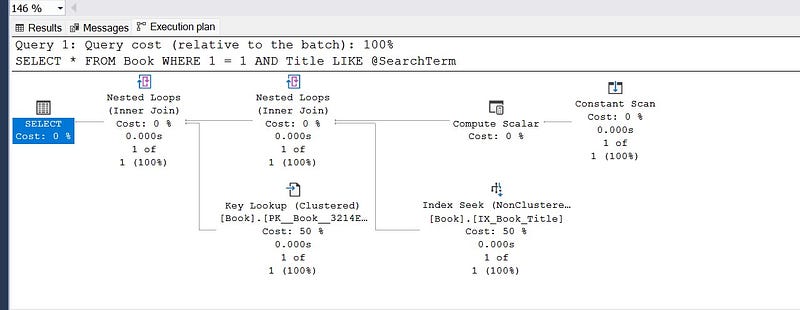
(ii). Using OPTION (RECOMPILE)
create or alter procedure GetBooks
@SearchTerm nvarchar(40)=null
as
begin
set nocount on;
select * from Book
where @SearchTerm is null or Title like @SearchTerm+'%'
option (RECOMPILE);
end
-- executing the procedure
exec GetBooks @SearchTerm='The Epic Of Gilgamesh'; -- returns 1 row
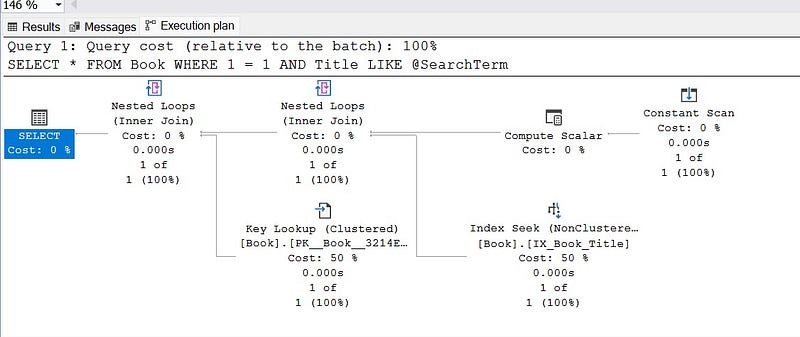
RECOMPILE causes increased CPU usage. In the most cases it won’t be a huge problem. If it is then consider using dynamic sql. But first look for the RECOMPILE. If a query has long compilation time and it runs frequently then consider dynamic sql. It is explained in depth by Gail, check it out, it has an amazing depth.
5. Using OR In where conditions
SELECT
SalesOrderID,
OrderDate,
SalesOrderNumber,
CustomerID
FROM
Sales.SalesOrderHeader
WHERE
CustomerID= 29642
OR
OrderDate < '2011-10-31';
In the table Sales.SalesOrderHeader, the column CustomerId has a primary key. And I have defined convering index On OrderDate (SalesOrderID, CustomerID).
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_OrderDate_Covering
ON Sales.SalesOrderHeader (OrderDate)
INCLUDE (SalesOrderID, CustomerID)
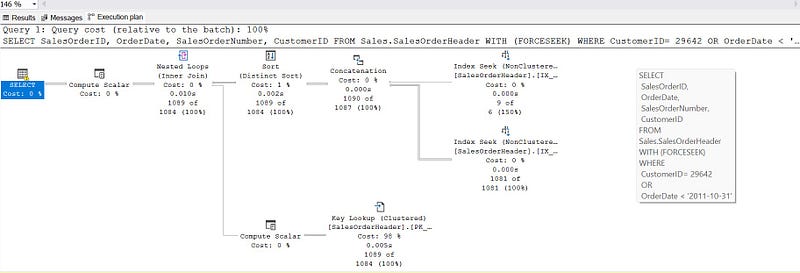
Execution plan:

This query looks for two different conditions and end up in index scan.
👉 One solution is to use FORCESEEK hint as mentioned here:
SELECT
SalesOrderID,
OrderDate,
SalesOrderNumber,
CustomerID
FROM
Sales.SalesOrderHeader
WITH (FORCESEEK)
WHERE
CustomerID= 29642
OR
OrderDate < '2011-10-31';
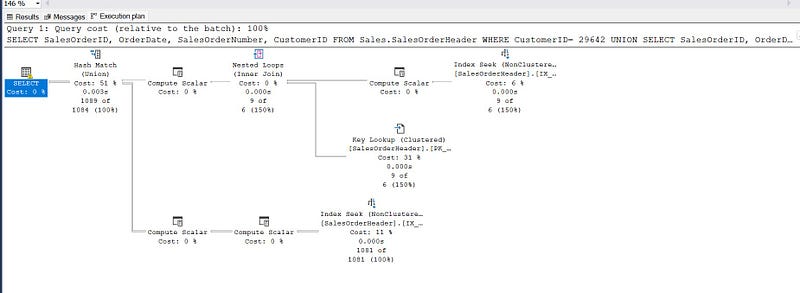
👉 Another solution is to use union:
SELECT
SalesOrderID,
OrderDate,
SalesOrderNumber,
CustomerID
FROM
Sales.SalesOrderHeader
WHERE CustomerID= 29642
UNION
SELECT
SalesOrderID,
OrderDate,
SalesOrderNumber,
CustomerID
FROM
Sales.SalesOrderHeader
WHERE OrderDate < '2011-10-31';
One more thing
It is not exactly related to the index but it is related to performance. Do not use OR with JOIN. I’ve personally never encountered this situation but I found it here during the research for this article. I have simulated the situation and presented it to you.
SELECT DISTINCT c.name, o.order_id, o.amount, o.status
FROM customers c
LEFT JOIN orders o
ON c.id = o.customer_id
OR c.email = o.customer_email
Execution plan:
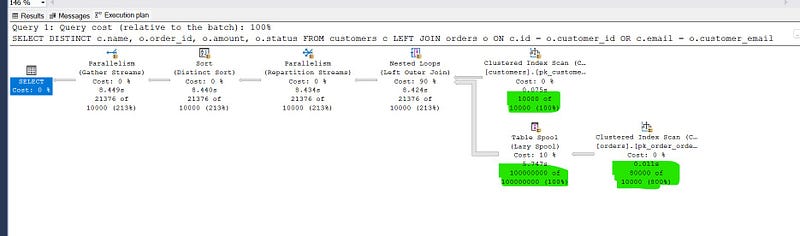
Statistics:
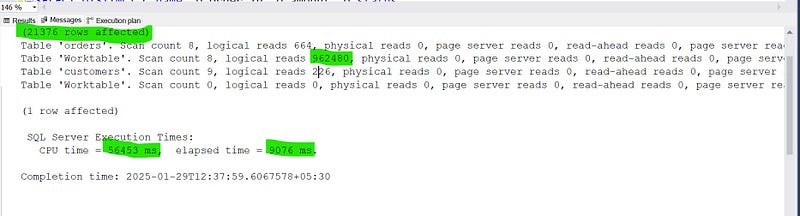
This query took considerable amount of time to run. Even I have only 10k records in each table.
We can use union to tackle the situation.
SELECT c.name, o.order_id, o.amount, o.status
FROM customers c
LEFT JOIN orders o ON c.id = o.customer_id
UNION
SELECT c.name, o.order_id, o.amount, o.status
FROM customers c
left JOIN orders o ON c.email = o.customer_email
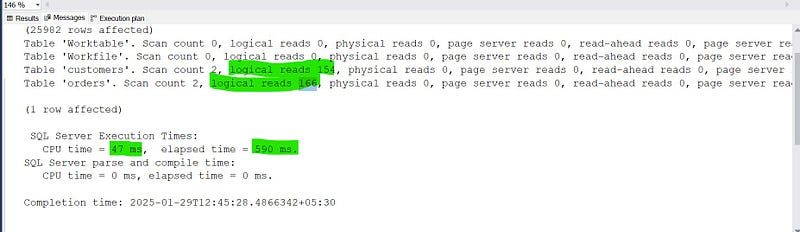
This query took less time and logical reads.
Summary
Any of these points do not always scan the table. This only happens when you have large data set (I am talking about thousands of records). Sql server optimizer is smart enough to optimize a query (thats why it is hired). But it is always good to follow these things.
If we sum up, don’t do this:
- where some_function(some_column)= some_value.
- where some_column like %search_string%
- where some_nvarchar_column= integer_value
- where column_name=@some_parameter or @some_parameter is NULL
- where condition1 OR condition2;
References
These are the list of articles I’ve followed during my research. They are amazing and provides depth. If you want to deep dive then you must checkout them.
- Non-SARGable Predicates (by Brent Ozar)
- SQL Server Implicit Conversions Performance Issues (by K. Brian Kelley at mssqltips.com)
- When SQL Server Performance Goes Bad: Implicit Conversions (by Phil Factor at red-gate.com)
- SQL Server Index Scan when using ‘OR’ operator (dba.stackexchange.com)
- The Only Thing Worse Than Optional Parameters For SQL Server Query Performance (by Erik Darling at erikdarling.com)
- Revisiting Catch-All Queries (by Gail at sqlinthewild.co.za)
- Performance Problem When Using OR In A JOIN (by Eric Cobb at sqlnuggets.com)
