Table structure and total records
Let’s look at our table structure as shown in the left panel of the picture
Note: There is a non-clustered index on the Title column of the Book table, which has a total of 1 million records.
select
Id,
Title,
Author,
Price
from Book where title='The Divine Comedy'
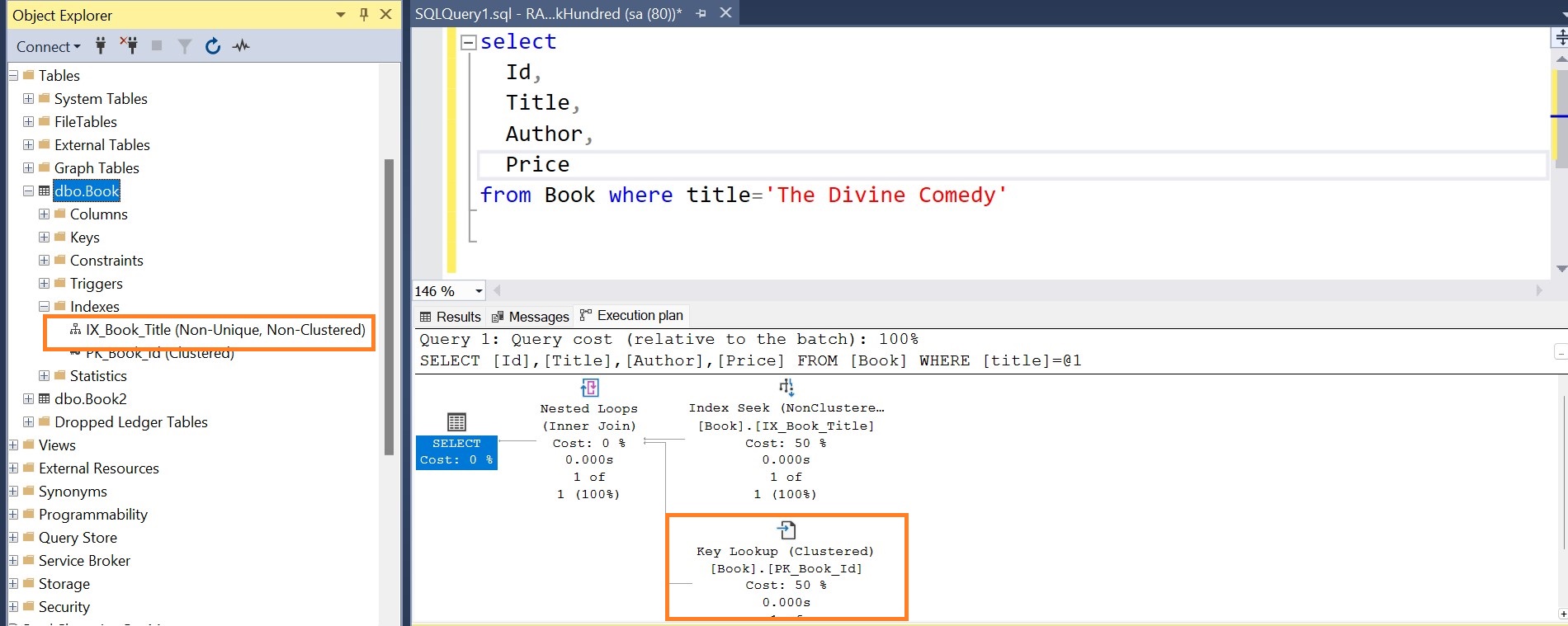
As you have noticed in the execution plan, there is a key lookup. Since index is only available for the Title column, Title is retrieved from the non-clustered index. However, other columns like Id, Author and Price are not present in the non-clustered index, so they will be retrieved from the clustered index (the Book table). This results in an additional key lookup step and may decrease the performance. It’s like, you are looking for records in two places (non clustered index and clustered index).
It might be easier to understand with picture:
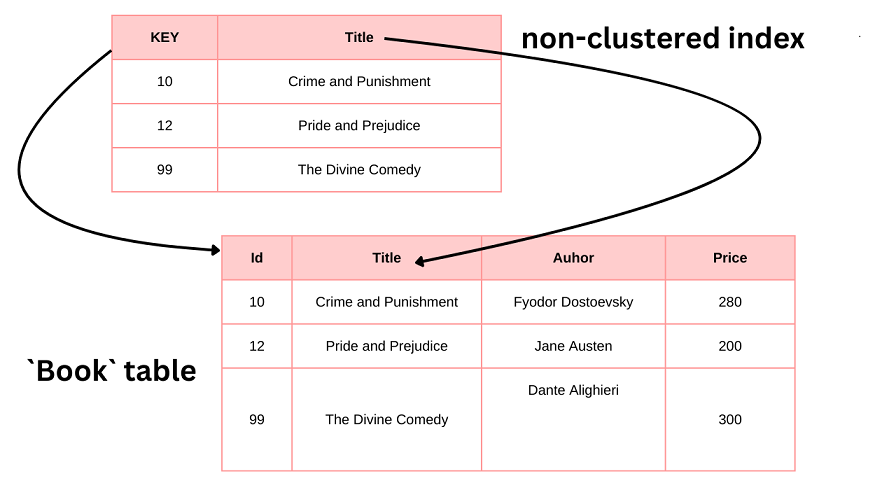
First, I am going to drop the existing index of Title column.
drop index if exists IX_Book_Title on Book
Let’s include those columns with the Title
create index IX_Book_Title_Inc_Id_Author_Price
on Book(Title)
include (Id,Author,Price)
In this step, we have created a Covering Index.
Let’s execute this query again:
select
Id,
Title,
Author,
Price
from Book where title='The Divine Comedy'
Execution plan:
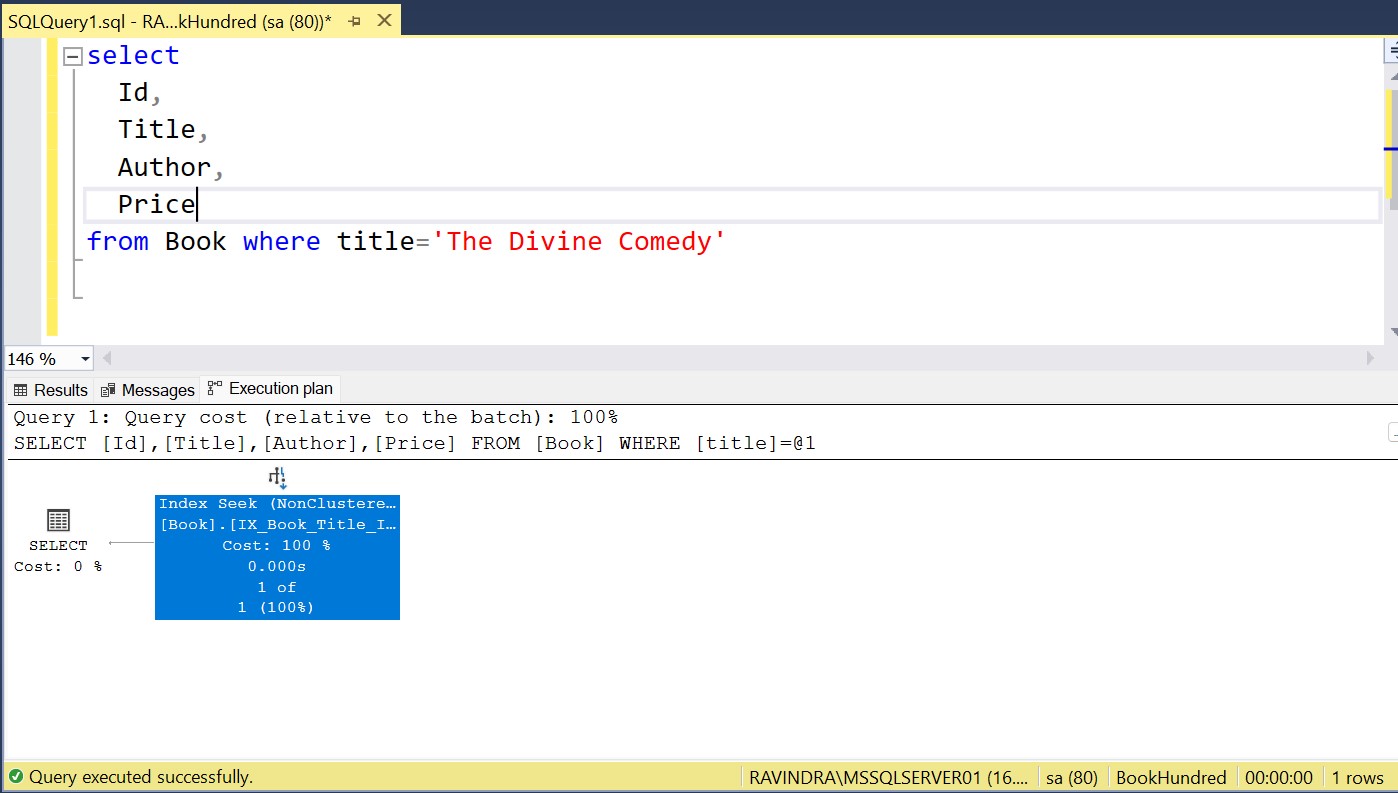
Now, the Key lookup is gone. All the queried columns are present in the non-clustered index.
Downsides
- It takes additional space to include those columns.
- Decreases the write performance. If your application is write heavy then re-consider it.
