Initially, it was not intended to be an article. I was tinkering around sql and documenting few things, then I thought, it could turnout to a nice article. I have wrote lots of article and created lots of videos on c#, .net core and angular. But it is my first article on the SQL.
In this blog post, we are going to explore few terms of execution plan, like table scan, clustered index scan, index seek, RID lookup and key lookup.
⚠️ If you follow along and execute the queries, it would be more beneficial.
Tools and tech used
- SQL Server 2022
- SQL Server Management Studio (GUI Tool)
So lets get started.
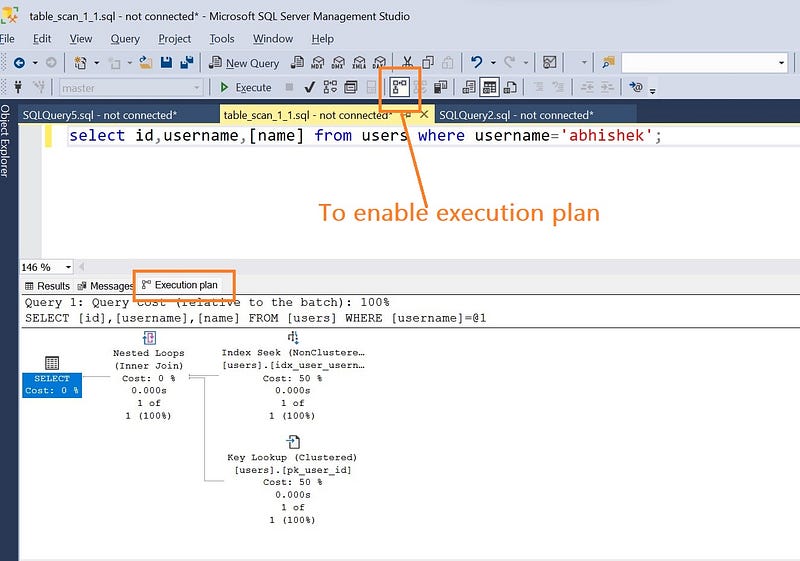
To enable the execution plan, select tab include actual execution plan(ctrl+m) as shown in picture. Then execute the query as usual and we will notice the tab execution plan , where you can see the execution plan.
Heaps and table scan
Use the following script to create the table.
use master;
go
drop table if exists users;
create table users(
id int identity,
username nvarchar(100)
);
go
insert into users(username)
values
('ramesh'),('Abhishek'),('arun');
go
The table users does not have any primary key. In fact, there is not any key at all in this table. Let’s execute the query below.
select id,username from users;
Execution plan:
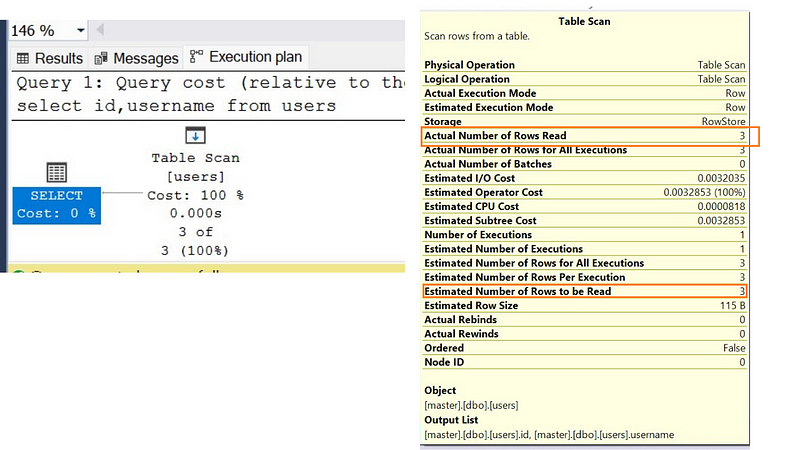
As you have noticed, total 3 rows have been read and sql server has performed a table scan, which means, it has to scan all the rows. That is expected since we are retrieving all the data.
Let’s execute the same query with where clause.
select id,username from users where id=1;
execution plan:
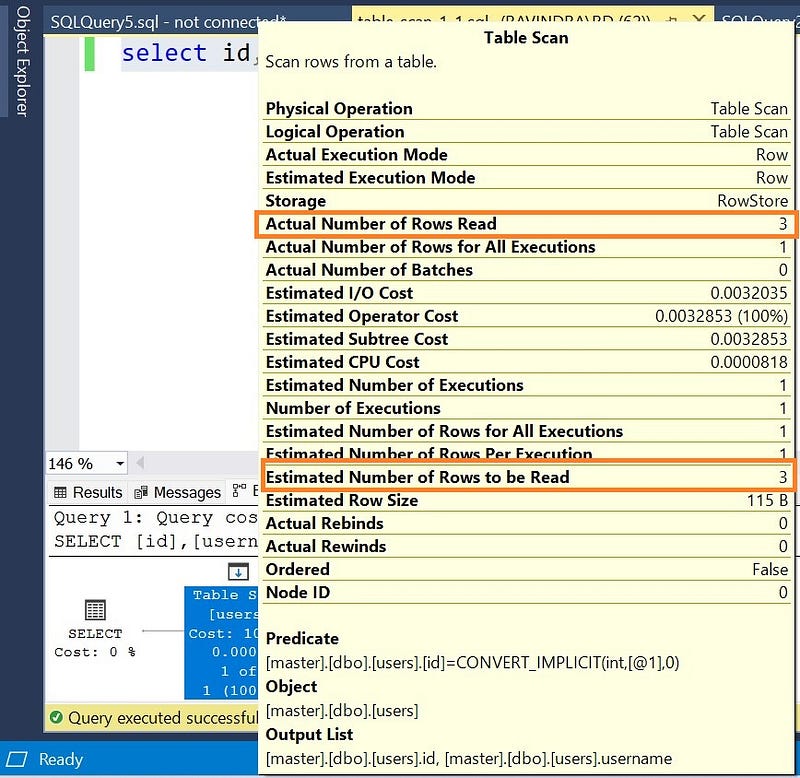
There is only one record with id=1, and sql server is reading 3 rows (we have total 3 rows). To retrieve just one record, sql server have to scan the whole table. It is called a table scan.
Let’s execute another query
select id,username from users where username='abhishek';
As the previous query, it will also perform the table scan and read all the rows to get a record with username = ‘abhishek’. If we would have thousand of rows, it had read all thousands rows. To find a single record we have to scan the entire table. Which is not a good thing if we have large data set.
Right now, our table does not have any clustered index. In sql server, a table without a clustered index is called heap. It means, our data is not stored physically in a sorted sorted order.
Clustered index and clustered index scan
Let’s add primary key at id.
alter table users
add constraint pk_users_id primary key (id);
By creating a primary key, a clustered index is automatically created. The clustered index is added at the column id. Now, table is no more a heap. When a table has a clustered index, the table is called a clustered table. Table is physically stored in a sorted order (sorted by id).
Let’s execute this query.
select id,username from users where username='abhishek';
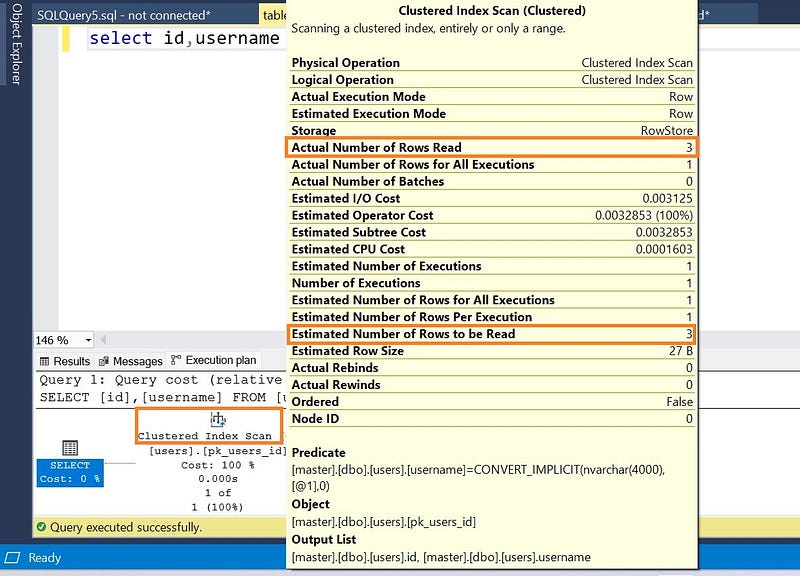
As you have noticed in the execution plan, it is showing Clustered Index Scan. To find a record with username = ‘abhishek’, sql server have to scan all the rows from the clustered index. It is called a clustered index scan.
Clustered index seek
Let’s execute this query.
select id,username from users where id=1;
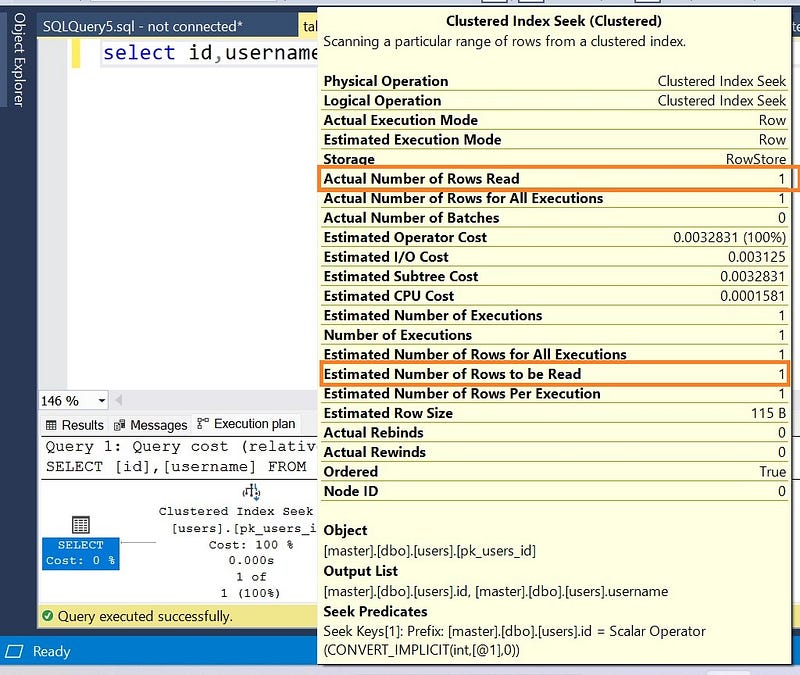
Now you have noticed Clustered index seek in the execution plan and sql server is only reading the 1 row to get the record with id=1.
- We are searching the record with id=1. The database engine knows exactly where to look. It’s like a book, where all the records are organized with page numbers. We just have to open the page 1 (or any page) and we can access the information on this page.
- Similar to the books, sql server jumps directly to the record with id=1 and reads related columns. It is called
index seek, which is the most performant.
Non clustered index on heap table
Let’s drop the table and recreate it. Now, I am dropping the primary key and **creating a index on the username.
use master;
go
drop table if exists users;
create table users(
id int identity,
username nvarchar(100)
);
go
create index idx_user_username on users(username);
go
insert into users(username)
values
('ramesh'),('Abhishek'),('arun');
go
Now let’s execute a query.
select id,username from users where id=1;
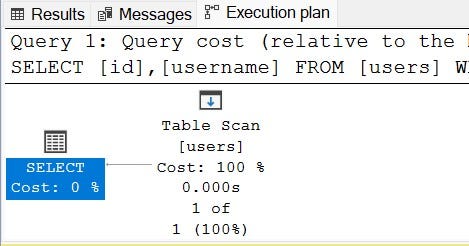
The execution plan stats, it is a table scan. That’s obvious, because we don’t have any index on the column id and we are filtering the records with id.
Now, let’s try to filter records with username.
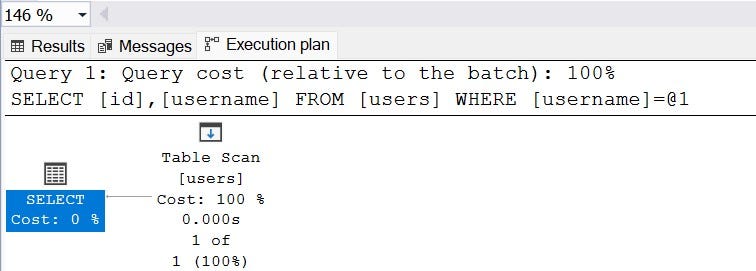
Execution plan is stating that it is a table scan. But, it should be an index seek, because we have an index on the column username. Why is it a table scan? Well, right now the table have 3 records only. Sql server assumes that table scan would be much faster than a index seek. Let’s add few more records. I am going to insert 999997 more records to the users table.
;with numbers
as
(
select 4 as n
union all
select n+1 from numbers
where n<999997
)
insert into users(username)
select concat('name',n) from numbers
option (maxrecursion 0);
I have used the recursive cte to achieve faster insertion.
⚠️ I have messed up with math, and couldn’t able to add 1M records.🤭
Let’s execute the same query.
select id,username from users where username=‘abhishek’;
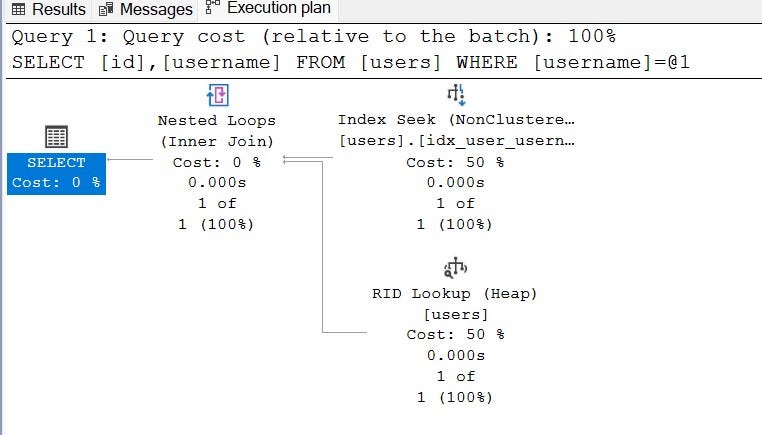
Now, sql server have performed a index seek (non clustered).

Since our table does not have a primary key, which means it does not have a clustered index, which means our table is a heap. And records are not stored physically in a sorted order.
It is how a heap with non-clustered index is stored (not exactly, but something like this).
Heap table (users) 👇
| RID | id | username |
|---|---|---|
| xx1 | 1 | ramesh |
| xx2 | 2 | abhishek |
| xx3 | 3 | arun |
When a table is stored as a heap, every row has a 8-byte row identifier (RID). Which consists of the file number, data page number, and slot on the page (FileID:PageID:SlotID). Heap table is unstructured, records are stored without any order.
Let’s understand how the non-clustered indexes are stored.
Non clustered-index on username 👇
| username | RID |
|---|---|
| Abhishek | xx2 |
| arun | xx3 |
| ramesh | xx1 |
Non clustered index usernameis stored in a sorted order. Each username is linked to the RID (row id), which is a pointer of the heap table. Using the row id, sql server lookup the table’s remaining columns.
When we executes the query SELECT id, username FROM users WHERE username = ‘abhishek’, the SQL Server does the following things :
- Uses the non-clustered index to find ‘abhishek’ and gets its RID (xx2)
- Uses this
RIDto directly locate the row in the heap table - Retrieves the requested columns from that row
Index seek (non clustered)
Now lets add a primary key on the column name id.
alter table users
add constraint pk_user_id primary key (id);
⚠️ By adding a primary key, the table users is not a heap any more, it is a clustered index now.
Let’s re-execute ‘that’ query.
select id,username from users where username='abhishek';
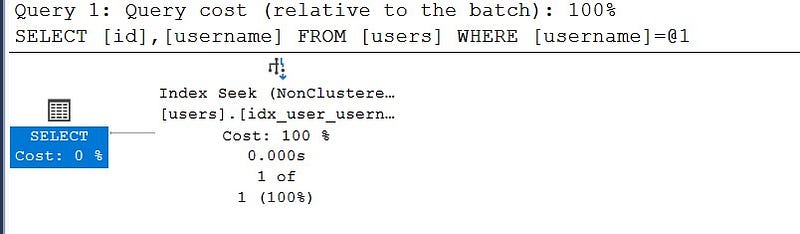
The execution plan is pretty straightforward. The database engine performs index seek(non clustered). Sql server will read only one row to retrieve the desired record.
Let’s add a new column named name to the table users and add a default value no-name to it.
alter table users
add [name] nvarchar(30) not null default 'no-name';
Now let’s execute this query.
select id,username,[name] from users where username='abhishek';
execution plan:
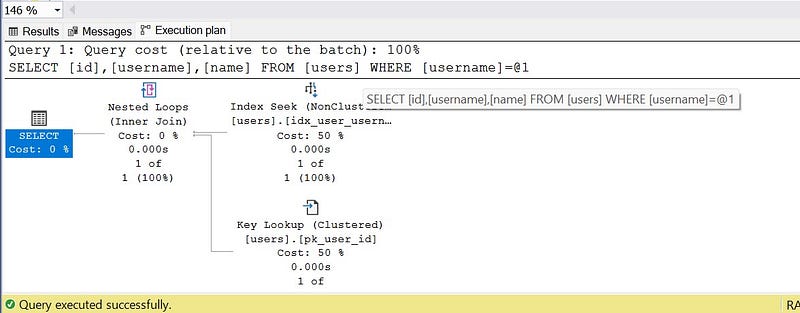
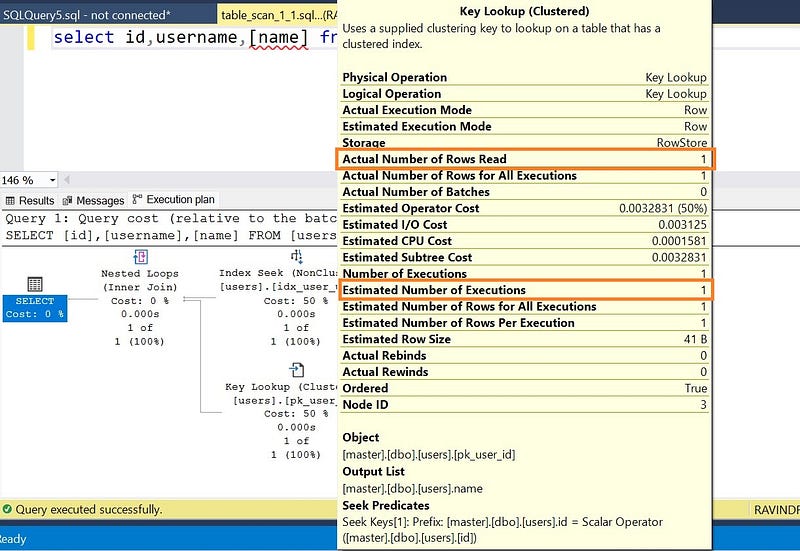
As the execution plan states, sql server has chosen the index seek and key look up for this query.
Our table has a clustered index and a non clustered index. Right now, we are retrieving the id,username and name. The column id has a clustered index, username has a non clustered index but name does not have any index. Since we are fetching a column (name) which is not a part of the non-clustered index. So database engine is performing key-lookup. Which was not happening in the case of select id,username from users where username=’abhishek’. Because all the columns that needs to be retrieved, are the part of some kind of indexes.
A
key lookupis the process of retrieving additional data from a table (with clustered index) that is not a part of the non-clustered index used for the query.
When sql server executes a query using a non-clustered index and needs columns that are not part of that index, it does:
Find the rows in the non clustered index
Then, use the clustered index key (or RID for heaps) stored in the non clustered index.
Finally lookup the additional column in the clustered index (or heap).
What happens when we execute our select query select id,username,[name] from users where username=’abhishek’.
In our case, a non-clustered index (on username) looks like this:
| username | id |
|---|---|
| Abhishek | 2 |
| arun | 3 |
| ramesh | 1 |
Since username is used in the where clause and username has a non-clustered index. Sql server does the following things:
- It scans non clustered index on username to find entries where username=’abhishek’.
- This non clustered index contains the value of
usernameand a pointer (clustered index, which isidin our case).
Since query also need the name column, which is not the part of non-clustered index. It can’t find ‘name’ in the non-clustered index, so it has to look for it. How it will look for it?
- It uses
idvalue found in the non-clustered index which is link to the clustered index (our users table).abhishekis associated with id=2 in the non-clustered index. - Sql server will look for the id=2 in the clustered table (users table) and can easily retrieve the row.
Summarizing key concepts
Heap
A table without a clustered-index is called heap. In heap table, every row has a 8-byte row identifier. Which consists of the file number, data page number, and slot on the page (FileID:PageID:SlotID). Heap table is unstructured, records are stored without any order. Heaps have their own use cases, you can learn more from the references provided in the end.
RID Lookup
Lookup into a heap table using a row id (RID). Non cluster indexes includes a row id to find the table data.
Key lookup
A key lookup is the process of retrieving additional data, which is not a part of the non-clustered index, from a clustered table (table with clustered index) . Key lookups use the clustering key (usually the primary key) as a pointer, rather than RID like in heaps.
Table scan
If a table does not have any index, the database engine have to scan the entire table to fetch the record(s), which is called table scan. Table scan is generally considered bad, but not always, if you have very small data set, the sql server may choose a table scan over the index seek.
Clustered index scan
The database engine look through all the records in the clustered table (table with clustered index, which is physically sorted).
Clustered index scan vs table scan
With table scan, the database engine scans data from a heap. With clustered index scan, the database engine scans data from the clustered table.
Index seek
Directly jump to the record.
References
- SQL Server Query Execution Plans for beginners — Clustered Index Operators
- What’s the difference between a Table Scan and a Clustered Index Scan?
- Key lookup and RID lookup in SQL Server execution plans
- Heaps (tables without clustered indexes)
- SQL SERVER Heaps: Understanding Their Benefits and Limitations
- What is heap table | Full table scan
- SQL SERVER — Heaps, Scans and RID Lookup
